Import Case Data
Importing case data is broken down into several steps, read the Before You Begin section before you start to import case data. The remaining tasks are as follows:
- Select the Data Source
- Match/Map Database Fields
- Edit/Update Mapping
- Validate Load File
- Complete the Import
Click on a section, below, to expand the section and complete the tasks contained within.
 Before You Begin
Before You Begin
Before you import case data into Administration, ensure that you read Overview: Import/Export. Then, for greatest efficiency, “walk through” the distinct steps in Administration. This will allow you to familiarize yourself with the information you will need and the options you will have.
To “walk through” the steps:
-
On the Dashboard, click the Administration module.

-
In the navigation panel, expand the Import/Export menu and click the Import Data work task.
-
Beginning with the first tab (Step 1) of the Import Data workspace, review and make a note of the information you will need for each step.
-
You need to understand the data you are importing so that imported fields can be correctly matched to the fields defined for the case. If needed, review the data you will be importing so you will know which fields and data types are being imported.
-
Consider the path information in your load file for image and/or native files. In Administration, you can edit the path as part of the import. You can also use a “volume” to make it easy to define the location of such files during import and to manage image file locations after import. A volume is a variable used to represent all or part of the path for image and/or native files for a specific case.
-
To limit the import to specific records that have specific content in a particular field, make sure you have defined that field as a Category field and included a control list as explained in Use Control List.
-
If you are importing data into an existing case (as opposed to a new case), consider when you will do so. Depending on the size of the database, system capabilities, and other factors, importing data may interrupt reviewer actions and consume significant system resources and time.
-
Continue with the procedures explained in this section.

If for some reason, your case fields do not quite match the imported data, make changes to the case before you import the data. See Edit Database Fields if needed.
|
|
IMPORTANT! Selecting options incorrectly during the import procedure (if the data does not match an option) will result in errors. Make sure you know the content of your import file and select these options only if they apply. |
If you are importing large amounts of data, it is recommended that you do so during “off hours” to minimize the impact to the system and your users, for example, at the end of the work day or on the weekend. Notify users who may work at these times of possible interruptions.
|
|
CAUTION: You cannot save a portion of a data import (such as your entries for steps 1 and 2). If you exit Administration before completing all steps, you will lose your work. |
Select the Data Source
After completing preparation, complete the following steps:
-
If your import file is open in another application, for example, a .CSV file is open in Microsoft Excel, close the file and the application.
-
In the Import Data workspace, click the Step 1. Select Source tab.
-
Select the client and case into which data is to be imported.
-
Job Name: If desired, replace the default job name with a name of your own choosing. This job name is used in the Import-Job History for the case. The log file path cannot be changed.
-
Import File: Enter the full path to the needed import file. Alternatively, click the
 button and navigate to and choose the needed file. Files may be any of the following types:
button and navigate to and choose the needed file. Files may be any of the following types:-
Document-level data: .CSV, .DAT, .DLF, .TXT, or .XML
-
Page-level data: .DLF, .LFP, .OLL, .OPT, or .XML
-
Document-level OCR (extracted text) files: .LST
-
-
Number of sample records: Select a sample of 1, 15, or 100 records. The initial lines in the import file are evaluated in order to display the number of records (documents and/or pages) specified here. If the selected number of records is not defined within the lines that are evaluated, then the sample will be smaller than specified.
-
First line is a header: Select this option if the first row in the import file contains column titles instead of data. (Some file types, such as .OPT, will select this option automatically.)
-
Sample Data: Review the excerpt of data from the import file.
-
Delimiters: If the data imported includes delimiters other than the standard types, change the delimiters to match the file. For details on default delimiters and instructions on using custom delimiters, see Delimiter details.
Ignore any delimiters that are not pertinent to your load file. (The entries in this area will be ignored if they do not apply to your load file.)
-
Field: Select the character that separates each field.
-
Quote: This optional delimiter typically marks the beginning and end of a field (as in .CSV files).
-
Newline: Select the character that signifies the start of a new line in the load file.
-
Multi-Value: Select the character that separates values within MULTI_VALUE fields.
-
Merged Fields: Administration allows you to merge multiple fields (in Match/Map Database Fields. For example, you may be importing a case in which two fields were used for a large amount of text.
-
If you want to merge fields, but also want an indicator of the original field separations, specify the delimiter here. The delimiter will be included in the merged data to identify the original field delineation(s).
-
Nested Value: If the case you are importing includes groups of or nested tags, select the delimiter that distinguishes groups, tags, and/or nested tags. For more information, see Nested (Parent/Child) Tags.
When delimiters have been defined, review the Sample Data to ensure it appears as intended.
-
-
Date Format: Select the date format that most closely matches the dates in your import file. For example, if your file includes dates in the format of
dd-mm-yyyy, select the D/M/Y option. Also note the following:-
Dates to be imported must be in a common date format. (For example, 27-09-2009 or 27 Sept 2009.)
-
If you are importing data from a .DLF file, the format must be
Y/M/D. -
Administration uses Microsoft's date interpreter/parser to interpret dates. Dates such as Friday June 15th, 1998 are possible, but if that date actually fell on a Saturday, then an error would be logged during import and the erroneous date would not be imported.
-
-
Document Tag Option (LFP only): .LFP files contain page-level tag details (not document-level tags). If importing from an .LFP file, select this option if you would like to change the page tags for the first page of each document to be document tags in Review. If you do not select this option, all tags in the .LFP file will be defined as page tags in your case. See the following table for details on making a selection.
-
If you do not check the option, the resulting import will mirror the .LFP exactly, with page tags only.
-
If you check the option, the resulting import will mirror the .LFP except for the first pages of documents. If those pages include tags, then those tags will be defined as document tags.
-
The import process imports/updates only those records specified in the .LFP. Therefore, related documents are updated only if they are specified in the .LFP file.
-
If an .LFP file indicates that a tag to is be set for an existing record and that tag is exclusive (that is, only one tag in its group can be selected), the import will change the tag.
-
Not all .LFP commands are supported—supported commands include: AN, FT, IM, IS, OF, OI, OT, VN. Unsupported commands are ignored.
-
When images are imported via an .LFP file, ENDDOC and ENDATTACH values are identified by Administration and added to the fields automatically.
-
Batch Import: To select additional files to import, complete the following steps. If the file selected in step 5 is the only file to be imported, skip to Match/Map Database Fields.
Files must be of the same type and have the same fields as defined in the file specified in the Import File field.
-
Determine whether you are adding a single file, a directory of files, or multiple recursive directories.
-
In the Batch Import area, click the Add button.
-
Navigate to and select the needed file(s), then click OK. Use Shift+click or Ctrl+click to select a contiguous or noncontiguous set of files, respectively.
-
If needed, repeat steps b and c to locate and select additional files.
-
Review the files listed in the File Name list. If a file should not be imported, click the file in the list and then click Remove.
-
When the set of files is correct, continue with Match/Map Database Fields.
-
|
|
NOTE: If you need to import multiple files at once (for example, a service bureau has provided multiple files for a case), select any one of the files to be imported now. Additional files will be selected in step 12. |
The columns in the table will differ, depending on which type of file is being imported. If you are importing an .LFP or OPT file, columns will be similar to this figure.

For these file types, Boundary column will always show “Document,” and the Pages column will show the number of pages in the document.
If default delimiters are not used in your load file, the sample data will not display correctly. In this case, continue to step 10.
|
If case has... |
Then... |
|
Page-level tags only |
Do not check the .LFP option. The resulting import will mirror the content of the .LFP file. |
|
Document-level tags only |
Check the .LFP option if you want the page tags on the first pages of documents to be “converted” to document tags in the case. |
|
Both page- and document-level tags |
You may or may not want to check the .LFP option. |
|
|
NOTE: Regarding imports from .LFP files: |
Delimiter details
This information supplements step 9 of Select the Data Source.
Default delimiters
Administration includes default delimiters based on file type, as listed in the following table. In this table:
-
A box, □, represents a nonprinting character.
-
“NA” indicates the delimiter is not applicable to the file type.
|
File Type |
Field |
Quote |
Newline |
Multi-Value |
Merged Field |
Nested Value |
|
.CSV |
, (0044) |
" (0034) |
(none) |
; (0059) |
(none) |
(none) |
|
.DAT |
□ (0020) |
þ (0254) |
® (0174) |
|||
|
.DLF |
(none) |
NA |
(none) |
|||
|
.LFP |
, (0044) |
" (0034) |
(none) |
|||
|
.LST |
, (0044) |
" (0034) |
(none) |
|||
|
.OPT |
, (0044) |
" (0034) |
(none) |
|||
|
.TXT |
, (0044) |
" (0034) |
(none) |
|||
|
.XML |
(none) |
(none) |
(none) |
Create custom delimiters
Certain import files, such as .CSV, .DAT, or .TXT, may include custom delimiters. To select a custom delimiter in step 9 of Select the Data Source:
-
In the needed delimiter field, select Custom. (You will need to scroll to the bottom of the delimiter list.)
-
In the Create Custom Delimiter dialog box, click the Characters or ASCII Values option, depending on how you will specify the delimiter character(s).
-
If you select Characters, enter the character(s) in the top field under the Characters option. Separate more than one character with a space. The ASCII value for each character appears in the bottom field.
-
If you select ASCII Values, enter the ASCII value(s) for the needed character(s) in the top field under the ASCII Values option. Separate more than one value with a space. The character corresponding to each value appears in the bottom field.
-
When finished, click OK.
Match/Map Database Fields
Overview
If you are importing document data, match (map) the data fields defined in the imported file to the fields defined for the case in Administration. Note:
-
Some fields in the import file can be omitted (not mapped) if needed. For example, the import file may have a Word Count field that is not needed in the case.
-
More than one field in the import file can be mapped to a single field in the case. For example, the import file may have two fields to define an author’s name (First Name, Last Name). In the case, a single field may be used for this information (Name).
|
|
NOTE: If you are importing image data (such as from an .LFP or .OPT file), matching of database fields may not be required. See Map Image Data and OCR Text Files. |
-
Several options relate to field mapping. For example, Administration allows you to correct the file path information in the import file so that the data will be correct in your case.
-
The following procedures comprise this step of the import process:
When finished mapping, proceed to Edit/Update Mapping.
Map Fields Using Auto-Selection
Administration can attempt to match the fields based on the field position or name. For example, if the input data contains a column called IMGKEY and the case contains a field named IMGKEY, it will automatically line up the source and destination field.
To auto-select fields:
-
After completing Select the Data Source, click the Step 2. Map Fields tab in the Import Data workspace.
-
To match by field name, ensure that your imported data includes field names in the header and that First line is header is selected in the Step 1 tab. In the Import Data workspace, click the Step 2. Map Fields tab.
-
Click the Auto-Select By Field Position or By Field Name button.
-
Evaluate the matching to determine if:
-
the auto-matching does not meet your needs, and/or
-
Some fields cannot be matched (in which case, the word Select in the Database Field column will be red).
-
-
If any problems exist, continue with Map Fields Manually.
-
When all fields to be included are matched, continue with Edit/Update Mapping.
|
|
NOTE: For auto-selected matching, make sure that one of the import fields is matched to the BEGDOC field defined for the case. |
Map Fields Manually
To manually match the fields:
-
In the Import Data workspace, click the Step 2. Map Fields tab.
-
Evaluate the Import Field listing to determine which fields will be included in the import.
-
For each field to be imported, click in the Database Field column and choose the database field you want to match to the import field. The list shows the field name and type to assist you with matching.
-
Repeat step 3 for all fields to be included.
-
When all fields to be included are matched, continue with Edit/Update Mapping.
|
|
NOTES:
|

Map Fields Using a Field Template
If you will be importing multiple load files separately (not as a batch), you can set up needed field mapping, save a template, then use the template to easily map fields for additional imports.
Create field template
-
On the Step 2 tab of the Import Data workspace, map fields using one of the previously described procedures.
-
Click Save Field Template.
-
In the Save Template File dialog box, navigate to an appropriate location for the template, enter a template file name, and click Save. An .XML-based field template is created. Field mapping and path correction data is maintained in the template.
Use field template
After creating a field template as described in the previous procedure, use it as follows:
-
On the Step 2 tab of the Import Data workspace, click Load Field Template.
-
In the Load Template File dialog box, navigate to the needed template, select it, and click Open. Mapping selections and path corrections will be made according to the template.
-
Review mapping details and make changes if needed.
-
When finished, continue with Edit/Update Mapping.
Map Image Data and OCR Text Files
If you are importing image data (such as from an .LFP or .OPT file) or an .LST file for OCR text, matching of database fields can often be skipped, as discussed in the following paragraphs.
.LFP files
If you are importing an .LFP file, note that Administration will automatically match the necessary fields. If applicable, two additional fields can be mapped:
-
IM lines: If boundaries specified in IM (Load Image Master Record) lines include a “C” as shown in the following example, then a relationship will be created if you map a BEGATTACH field (and that field references the BEGDOC of the parent document):
-
OF lines: Original File (OF) for EDD Image lines correspond to NATIVE fields in Review. If your .LFP file includes OF lines, you must map a NATIVE field if you want to import that information.
IM,000010,C,0,@001;IMG_0001;000010.tif;2,0
.LST and .OPT files
If you are importing an .LST or .OPT file, Administration will automatically match the necessary fields, so users should skip to Edit/Update Mapping.
Edit/Update Mapping
After completing field mapping discussed in the previous procedures, complete the following procedures as they apply to your data.
Check/Correct Path Information
You can easily check any file path information (for the image path, text, and/or native files) contained in the load file and change it to “point to” the correct location for the files being added to the case.
To change path information for files used in your case:
-
On the Step 2 tab of the Import Data workspace, locate an import field that includes a file path/file name (the Image Path or a mapped EXTRACTEDTEXT or NATIVE field), click
 next to the corresponding Database Field field. Administration will check the path and file name.
next to the corresponding Database Field field. Administration will check the path and file name.-
If the specified file exists at the specified location, a success message will display. Click OK and skip to step 3.
-
If the specified file does not exist at the specified location, an error message will display. Complete step 2.
-
-
To correct file paths, click OK in the error message and complete the Edit Path dialog box as follows:
-
Load File Path: Review the path information to determine the part of the path that is incorrect and needs to be replaced.
-
Replace Text: Enter the incorrect portion of the load file that you identified in step a.
-
With: Enter the correct file path information, either the path itself or a volume name that represents the correct path details. Note:
-
For path entries, either type the path or click
 to navigate to and select the needed file location.
to navigate to and select the needed file location. -
If entering a volume name, precede and follow the volume name with the “at” sign, @, as in @VOL1@. For details on entering volume information, see Search/replace examples.
-
TIP: You can select/copy the incorrect portion of the path in the Load File Path field and then paste it in this field.
-
-
Imported Path: Review the corrected path for accuracy:
-
If needed, click
 to update the path in the Imported Path field.
to update the path in the Imported Path field. -
To verify that the path is correct, click
 . If the file is not found, check your work and make corrections as needed.
. If the file is not found, check your work and make corrections as needed. -
When the validation message states File found!, click OK.
For volumes, the complete path represented by the volume (and the portion of the load file path that you are not replacing) displays beneath the Imported Path field.
-
-
Repeat these steps for each type of path in the load file.
-
As needed, continue with another procedure described in this section. If no additional options on the Step 2 tab need to be set, go to Validate Load File .
|
|
TIP: If the path you enter is not valid, check your entries carefully. For example, look for missing or extra backslashes such as |

Select Import Mode for Data
Complete the following steps to define how data will be added to a case.
-
On the Step 2 tab of the Import Data workspace, in the Select Mode section, select the way in which data is imported into the case, as explained in the following table.
Import Mode Options
Option
Description
Append All Records
Use this option to add new records to a new or existing database.
-
For a new case, all records in the load file will be added to the database.
-
For an existing case:
-
Records in the load file that do not currently exist in the case will be added to the database.
-
Records in the load file containing fields that match those already populated in the database will not update those populated fields.
-
The load file must contain a BEGDOC, DOCID, or IMAGEKEY field.
Overlay/Append
Use this option to update existing records and add new records to an existing database. Selected records can be updated as described in step 2.
-
Records in the load file that do not currently exist in the case will be added to the database.
-
Records in the load file that are also in the existing case will overwrite only the fielded information in the database with the fielded information contained in the load file. The following example shows the effect of an import when this option is selected.
Load File
“Pet” FieldCase “Pet Field”
Before Import
After Import
dog
(blank)
dog
cat
dog
dog
dog
(blank)
dog
(blank)
Overlay Only
Use this option to update existing records. Selected records can be updated as described in step 2.
-
Records in the load file that do not currently exist in the case will not be added to the database.
-
Records in the load file that are also in the existing case will overwrite only the fielded information in the database with the fielded information contained in the load file (see the previous example).
Tag Import
Use this option to import tags from a plain text file and apply them to records in the case. Tags can be imported from a plain text file as described in Text file tag-import details .

NOTE: Do not select this option if you are importing from an .LFP file with IS lines only. (In that case, choose from the previous options, depending on whether you want to add new tags only, update existing tags, or both.
-
-
Overlay Field to Match: If you select either of the Overlay options in step 1, select the field to be used for matching the load file records to the case records. This is typically the BEGDOC or DOCKEY field, but may be another field. If importing tags, this must be the BEGDOC field.
-
As needed, continue with another procedure described in this section. If no additional options on the Step 2 tab need to be set, go to Validate Load File .
Text file tag-import details
This information supplements Select Import Mode for Data. Tag details can be imported using a plain text file (such as a .CSV or .TXT file) containing image keys and tag information for each record for which tags are to be applied. The following figure shows the content of a typical text tag-import file. In this example, tag groups, tags, and nested tags are being imported.

Tags defined in the import file will be created in the case if they are not already defined for the case.
To import tags successfully, ensure that the issues in the following table are addressed.
|
Issue |
Description |
|
|
File format |
|
|
|
Wrong: |
|
|
|
Right: |
|
|
|
Delimiters |
When you complete Select the Data Source:
|
|
|
Overlay field |
When you complete Select Import Mode for Data, make sure the Overlay Field to Match is set to the BEGDOC field. |
|
|
Import options |
Before performing the import, address the following:
These options are selected during Complete the Import . If tag groups are not defined, tags will be placed in an “Imported Tags” group. |
|
Select Image File Options
Complete the following steps to select image handling options and correct the image path if needed. If you are importing tags, skip this procedure.
-
Ensure that the Step 2 tab is selected on the Import Data workspace.
-
Image Options: If you are importing data into a new case that contains no data, leave the default selection and go to step 3.

CAUTION: If you are importing an .LFP file that does not include IM lines, these options do not apply. (That is, the file contains OT, OI, FT, IS, and/or AN lines only.) In this case, leave the default selection and go to step 3.
(In order for these options to apply, the .LFP file must have IM lines that correspond to AN lines for the same image keys.)
For other types of load files, select one of the following options:
-
Create error if image exists: If the image key specified in the import file exists in the case, an error is logged and the image record is not created.
-
Overwrite and remove existing annotations: If the image key specified in the import file exists in the case, overwrite the record and eliminate any annotations (highlighting, mark-ups, and/or redactions) that were specified for the image.
-
Overwrite but retain existing annotations: If the image key specified in the import file exists in the case, overwrite the record and keep any existing annotations (such as highlighting, mark-ups, and/or redactions) that were specified for the image.
-
Skip existing images: If the image key specified in the import file exists in the case, leave the record for that image unchanged.
NOTE: If you select the Overwrite and remove existing annotations, ensure that the Rebuild Indexes after last Load File option is selected in Select Indexing Method regardless of load file size or type.
This selection causes re-indexing to occur after the import is completed, which provides a faster, more efficient approach when you are overwriting and removing existing annotations.
-
-
Image file path: If the path defined in the load file for image files in the load file is incorrect, click Edit File Path in the Image Options area and complete the Edit Image Path dialog box:
-
Load File Path: Review the path information to determine the part of the path that is incorrect and needs to be replaced.
-
Replace Text: Enter the incorrect portion of the load file that you identified in step a.
-
With: Enter the correct file path information, either the path itself or a volume name that represents the correct path details. Note:
-
For path entries, either type the path or click
 to navigate to and select the needed file location.
to navigate to and select the needed file location. -
If entering a volume name, precede and follow the volume name with the “at” sign, @, as in @VOL1@. For details on entering volume information, see Search/replace examples.
-
-
Imported Path: Review the corrected path for accuracy.
-
To verify that the path is correct, click
 . If the file is not found, check your work and make corrections as needed.
. If the file is not found, check your work and make corrections as needed. -
When the validation message states File found!, click OK.
TIP: You can select/copy the incorrect portion of the path in the Load File Path field and then paste it in this field.
If needed, click
 to update the path in the Imported Path field.
to update the path in the Imported Path field. For volumes, the complete path represented by the volume (and the portion of the load file path that you are not replacing) displays beneath the Imported Path field.
-
-
As needed, continue with another procedure described in this section. If no additional options on the Step 2 tab need to be set, go to Select Text Options.
Select Text Options
If OCR text files are being imported as part of the load file, complete the following steps.
-
Ensure that the Step 2 tab is selected on the Import Data workspace.
-
In the Text Options area, select the Prompt on missing Text Files option if you want to receive a prompt for each case record for which an OCR text file does not exist.
-
.CSV or .DAT Load Files Only: If the EXTRACTEDTEXT field contains paths to OCR text files instead of the actual text, select the Extrct. Text contains File Path option. Text from the files will populate the EXTRACTEDTEXT field and Extracted Text tab for each document.
-
If the path defined in the load file for text files is incorrect and you did not make corrections during field mapping, click Edit File Path in the Text Options area and complete the Edit Text Path dialog box:
-
Load File Path: Review the path information to determine the part of the path that is incorrect and needs to be replaced.
-
Replace Text: Enter the incorrect portion of the load file that you identified in step a.
-
With: Enter the correct file path information or click
 to navigate to and select the needed file location.
to navigate to and select the needed file location. -
Imported Path: Review the corrected path for accuracy.
-
To verify that the path is correct, click
 . If the file is not found, check your work and make corrections as needed.
. If the file is not found, check your work and make corrections as needed. -
When the validation message states File found!, click OK.
TIP: You can select/copy the incorrect portion of the path in the Load File Path field and then paste it in this field.
If needed, click
 to update the path in the Imported Path field.
to update the path in the Imported Path field. For volumes, the complete path represented by the volume (and the portion of the load file path that you are not replacing) displays beneath the Imported Path field.
-
-
As needed, continue with another procedure described in this section. If no additional options on the Step 2 tab need to be set, go to Validate Load File .
Correct Native File Paths
If the path defined in the load file for native files is incorrect and you did not make corrections during field mapping, complete the following steps.
-
Ensure that the Step 2 tab is selected on the Import Data workspace.
-
In the Native Options area, click the needed button and complete the Edit Native Path dialog box as follows:
-
Load File Path: Review the path information to determine the part of the path that is incorrect and needs to be replaced.
-
Replace Text: Enter the incorrect portion of the load file that you identified in step a.
-
With: Enter the correct file path information or click
 to navigate to and select the needed file location.
to navigate to and select the needed file location. -
Imported Path: Review the corrected path for accuracy.
-
To verify that the path is correct, click
 . If the file is not found, check your work and make corrections as needed.
. If the file is not found, check your work and make corrections as needed. -
When the validation message states File found!, click OK.
TIP: You can select/copy the incorrect portion of the path in the Load File Path field and then paste it in this field.
If needed, click
 to update the path in the Imported Path field.
to update the path in the Imported Path field. For volumes, the complete path represented by the volume (and the portion of the load file path that you are not replacing) displays beneath the Imported Path field.
-
-
As needed, continue with another procedure described in this section. If no additional options on the Step 2 tab need to be set, go to Validate Load File .
Select Indexing Method
Review uses a comprehensive index of terms and data for each case added to the database, which allows search speed and performance to be optimized.
Complete the following steps to select the indexing method that will help ensure that your import into an IPRO Database is processed safely and has the least impact possible on your existing case.
-
Ensure that the Step 2 tab is selected on the Import Data workspace.
-
In the Indexing option area, click Edit Indexing Option.
-
Read the indexing option descriptions and select the option that most closely matches the current import circumstances.
-
Click OK.
-
As needed, continue with another procedure described in this section. If no additional options on the Step 2 tab need to be set, go to Validate Load File .
|
|
NOTE: If you selected the Overwrite and remove existing annotations in Select Import Mode for Data, select the Rebuild Indexes after last Load File option here regardless of load file size or type. This option is also the default and recommended setting if you are performing a batch import. Rebuilding indexes after the last load file causes re-indexing to occur after the import is completed, which provides a faster, more efficient approach when you are overwriting and removing existing annotations or importing from multiple files. |
Validate Load File
This procedure applies if you are importing from a load file. Skip this procedure if you are importing only tags.
To validate your import file:
-
On the Step 2 tab of the Import Data workspace, in the Action area, select Validate.
-
Click Submit.
-
When the process is completed, click View Results and complete step 4 (recommended) or step 5.
-
To correct errors, evaluate each tab of the Validation Results dialog box and refer to the following topics for details:
-
To ignore errors and continue with the import, perform one of the following steps. In this case, errors will need to be corrected after the import.
-
If validation is not required for the case (see note above), click Cancel in the Validation Results dialog box and continue with Complete the Import .
-
If validation is required for the case, continue with Complete the Import . When errors are found, you will be alerted and have the option to ignore the errors.
-
Manage undefined tags
Undefined tags are those that do not match tags in your case. Tags that do match your case will be imported. After completing Validate Load File , follow these steps to manage undefined tags:
-
Review the tags listed on the Tags tab of the Pre-Process Results dialog box, and the groups in the Tag Groups pull-down list.
-
Take the following steps as needed:
-
To create one or more new tag groups for undefined tags:
-
Click
 on the right side of the tab.
on the right side of the tab. -
In the Create Tag Group dialog box, enter a new tag group name and select needed group rules. For details, see Group rules.
-
Click OK.
-
Repeat steps a - c for other new tag groups.
-
Continue with the next step.
-
-
For each undefined tag to be imported, click the tag, then select the needed group from the Tag Group list.
Tips:
-
Right-click a tag to select the needed group.
-
To apply the same selection to multiple tags, click the first tag, then Shift+click the last tag to select a contiguous set of tags or Ctrl+click other tags to select a non-contiguous set.
-
-
Repeat step 4 for all tags to be imported.
-
Continue with other pre-processing tasks as needed. If none exist, go to Complete the Import .
Manage undefined redactions
Undefined redactions are those that do not match redactions in your case. Redactions that do match your case will be imported.
After completing Validate Load File , follow these steps to manage undefined redactions:
-
Review the redactions listed on the Redaction Categories tab of the Pre-Process Results dialog box. An ID of zero indicates that the redaction label is not found in the case.
-
Select the redactions you want to import and add to your case. For multiple redactions, click the first redaction, then Shift+click the last redaction to select a contiguous set of tags or Ctrl+click other tags to select a non-contiguous set.
-
When all needed redactions are selected, click Create Redaction Categories. An ID number will be assigned to all selected redactions.
-
Continue with other pre-processing tasks as needed. If none exist, go to Complete the Import .
Review undefined control list values
Control list values are the values defined for database fields for which the Category flag has been used. (See discussion of categories in About Database Fields.)
For your convenience, undefined control list values (those that do not match the values defined in your case) are automatically added to your case as part of the import process.
Follow these steps to review undefined control list values:
-
In the Pre-Process Results dialog box, click the Control Values tab.
-
Review the details as follows:
-
Control Field: Lists the field(s) that have been defined with the Category flag and have control list values.
-
Existing Control Values: Lists the control values defined in the case for the selected field.
-
Control Values from Load File: Lists control values found in the import file that are not defined in the case.
-
-
For each field listed in the Control Field list:
-
Click a field name.
-
Review the control list values that exist in the case and those in the load (import) file.
-
Repeat steps a and b for all fields listed.
-
-
Continue with other pre-processing tasks as needed. If none exist, go to Complete the Import .
Evaluate load file errors
The Validation function evaluates the load file for errors. After completing Validate Load File , follow these steps to check load file errors before you import case data:
-
In the Validation Results dialog box, click the Load File Errors tab.
-
Review the error summary in the top portion of the workspace.
-
To see the load file content for a particular error:
-
Select the error.
-
Select the Preview Load File option.
-
Review the actual load file content in the bottom portion of the workspace.
-
-
Your action will depend on the number and type of errors.
-
For severe problems, correct the load file or obtain a new one.
-
For few or minor problems, continue with other validation tasks as needed. If none exist, go to Complete the Import .
-
Complete the Import
Once all aspects of the import are defined, import the data as follows. Import settings can also be saved if desired.
-
On the Step 2 tab of the Import Data workspace, in the Action area, select Import.
-
Click Submit.
-
If you are importing tags, the adjacent message will display.
-
If the Require Validation of Load Files option is selected for the case, and load file errors are found, an error message will display as shown in the following example.
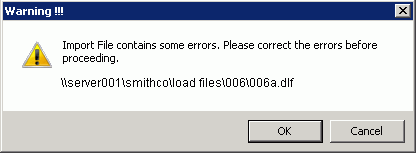
-
Click OK; the Validation Results dialog box opens.
-
Review load file errors and complete step c or d.
-
To correct errors, click Cancel, make corrections (see Evaluate load file errors), then repeat this procedure.
-
To ignore errors and complete the import, select the Accept Errors and Allow Import to Continue option.
-
-
Progress will display on the Step 3. View Progress tab. Read the information as it is presented. If error(s) occur, click Cancel to stop the import if needed.
-
If needed, when the import is complete, take one or both of the following actions:
-
If the status for a load file is shown as “Completed with errors,” click
 next to the error message. A text file containing error details will open.
next to the error message. A text file containing error details will open. -
Click the View button at the bottom of the tab to see overall details about the import. The import log (text) file opens; this file lists the fields that were mapped, options, selected, and start/stop information for each load file.
-
-
Next, click the Step 4. Verify tab.
-
Evaluate records as explained in . Possible activities include:
-
Reviewing the Documents list
-
Reviewing document details (for tag imports, reviewing tag information)
-
Deleting a document or page
-
Checking/changing image file path
-
Managing the volume used to define the image path
-
Viewing images
-
-
When finished, continue with other administrative activities.

Select the needed options. If you are importing tag group names, ensure that Make the Root Level the Group is selected; otherwise, tags will be imported to the group “Imported Tags.”
|
|
TIP: Reports to help you evaluate the imported records are available in Case Management. See Overview: Reports for details. |
Related Topics
Version: 2023.8.12
Last Revision: 11/8/2023