

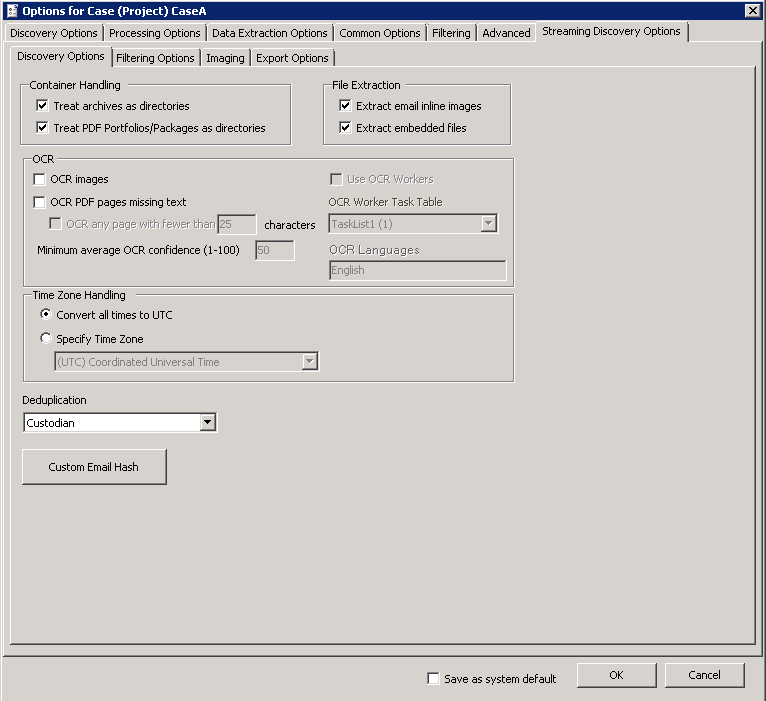
Streaming Discovery General Job Options
|
Option |
description |
|
Container Handling |
PDF Portfolio files allow email boxes to be stored/converted within a folder structure. As of version 2018.5.2, this folder structure information will be extracted and available for export in the existing ‘MailFolder’ metadata field. Treat archives as directories: This option is selected by default. The files in the archived folder will be treated as parent and child docs when running a Discovery JobIn eCapture, a single directory is chosen to run the discovery job from in order to determine file types. During the discovery process, the MD5 hash for files (sans container files) are calculated and indexing occurs.. In addition, WINMAIL.DAT attachments are treated like archives and will be processed like .ZIP files. The following are treated like archive files. |
|
File Extraction |
|
|
OCR |
After selecting the languages, click OK to close the dialog. The selected languages appear in the OCR Languages field. Place the mouse pointer on the OCR Languages field to display a tooltip that lists all the selected languages that were not visible in the OCR Languages field. The OCR Languages field is a read-only field. |
|
Time Zone Handling |
Convert all times to UTC: Default setting. Specify Time Zone: Select this option to specify a time zone to convert original times to the times for the selected time zone. For example, you might select the time zone of the workstation where the files originated. The selected time zone will be applied to MetadataMetadata describes how and when and by whom a particular set of data was collected, and how the data is formatted. Created by the native program (e.g. Microsoft Word, Outlook) and is maintained with the native file (the letter or e-mail). eCapture uses a component called Oracle® Outside-In Technology (formerly Stellent), which extracts the metadata from the native files during the electronic discovery process. metadata can show the history of a document, where it went, how it was used, what it “did”. It shows how a document was created, the date it was created, modified, and/or transmitted, and the person or persons who handled the document. output from the ADD Streaming Discovery worker. Updates to extracted text will only be applied to the header of emails (the Sent Date). |
|
De-Duplication |
A list of matching hash values will be retrieved for each parent document. The de-duplication scope will be determined by grouping the results by case (project) - e.g. all documents or by custodian. De-duplication is always performed at the parent level. If a parent is marked as a duplicate, then it, along with the rest of its family, will not be exported. From the de-duplication drop-down list, select one of the following: CustodianIn eDiscovery, the data custodian is usually the person responsible for, or the person with administrative control over, granting access to an organization's documents or electronic files while protecting the data as defined by the organization's security policy or its standard IT practices.: documents which are duplicates of any documents within the custodian will be removed. Default option. Case (ProjectIn ADD, the level beneath Client in the hierarchy. Projects can have one or more Custodians.): documents which are duplicates of any documents within the case (project) will be removed. None: all documents including duplicates are exported. |
|
Custom Email Hash |
Displays the Custom Email Hash dialog. Select from the following options: Some emails may have identical values in the properties that eCapture uses to generate hashes; however, the values may differ in the attachment contents. Family hash accounts for this by using the hash values of the extracted attachments to calculate a second hash for the email parent. As of version 2016.3.3, de-duplication may be performed on parent hash rather than family hash values for newly created Streaming Discovery Jobs using version 2016.3.3 only. (Note: Existing Streaming Discovery Jobs retain the family hash setting.) The default setting uses family hash. This setting is found in the DedupUseFamilyHash field of the ConfigurationProperties table for the eCapture Configuration database. The default value is 1. To switch to parent hash, change the value from 1 to 0 in the DedupUseFamilyHash field. If the value is set to 0 in the ConfigurationProperties table, then family hashes will not be considered when applying de-duplication. Method of gathering and creating the MD5Hash changed for newly created Cases (Projects). Hashing of e-mails uses the UTC time to ensure proper de-duplication across time zones. In most cases, MD5 hash values are calculated on the file itself. For more reliable de-duplication of emails though, it is required that de-duplication occur on the information contained within it and not the file itself. There are many reasons for this; the simplest is the fact that when an email is saved out of its container (PST, NSF, etc.), the file that is created contains information that would change the hash value of the same email each time that the email was saved out. When an email is discovered within eCapture, it is assigned a hash value based on fields chosen by the user. The values of these fields are concatenated and the text is hashed. Select from the following email fields to generate the hash value.
Select from either Creation Date or Last Modification Date. The selected value will be used when calculating the MD5 hash in the event that the normal E-mail Date value is not present. This commonly occurs for Draft messages that have not been sent. Start Time is always used if it exists. By default, Subject, From/Author, Email Date, and an Alternate Email Date of Creation Date are used for email hash generation. |
|
Save as System Default |
Appears when setting options at the Case (Project) Level. Select this option to retain these settings for future Cases (Projects) created for the ClientThe highest level in the ADD hierarchy. A Client is required to create a case.. The settings are saved to the eCapture Configuration database. The Settings.INI file is stored in the location path indicated during Case setup. The location path appears in the Client Management tab summary panel. |
|
Save Settings as Case (Project) Default |
Appears when setting options at the Job Level. Select this option to retain these settings for future ADD Streaming Discovery Jobs created for the Case (Project). The Settings.INI file is stored in the location path indicated during job setup. The location path appears in the Client Management tab summary panel. |

Related pages: