Manage Ingestion Settings
You can view and modify ingestion settings for a Processing case in OPEN DISCOVERY. These settings, which are also found in eCapture, offer you the flexibility of customizing how files are ingested into your case. Settings modified in OPEN DISCOVERY are updated in eCapture, and vice-versa.
Follow the instructions below to learn how to view and modify ingestion settings in OPEN DISCOVERY, as well as to review detailed definitions for each setting.
|
|
Note: There are additional ingestion settings available in eCapture. For further customization options, use the eCapture app. See Create a Streaming Discovery Job for more information. |

For a visual overview of Ingestion settings, see the below video.
View and Modify Ingestion Settings
To view and/or modify ingestion settings:
-
Open Case Management and locate the Processing case whose settings you would like to view or modify.
-
Click the hamburger icon corresponding to the needed case.
-
From the menu that appears, select Case Settings.
-
Click the Ingestion tab at the top of the Case Settings work area.

-
On this page you can view a selection of ingestion and filtering settings. To view and/or modify the full set of ingestion settings available in OPEN DISCOVERY, click the Manage Ingestion button.
-
Update settings as needed. See the table below for more information about these settings.
-
When finished, click the Save button in the top-right corner of the page. If you exit without saving, any changes you made will be lost.

Note: You can discard any changes you have made by clicking the Cancel button in the top-right corner of the page, or by exiting the page.

How Hash Values are Generated For Deduplication
Deduplication does not take into account the filename, but only the content, when hashing. Emails are a little different, and you may customize the fields used to generate the hash value. For documents that are part of a family, the entire family will be included when deduping.
Understand Ingestion Settings
Review the table below to learn more about the various ingestion settings you can update in OPEN DISCOVERY.
|
Setting |
Definition |
||||
|---|---|---|---|---|---|
|
Time Zone |
Select the time zone to be applied to extracted date metadata. Use the dropdown to locate the needed time zone. For more information about Time Zone Handling, see How IPRO eCapture Handles Dates and Time Zones. |
||||
|
Container handling |
Determine the treatment of archive (.zip, .rar, etc.) and PDF Portfolio/Package containers. When "Treat as containers" is selected all extracted files will be treated as a single family of documents with the container being identified as the parent. |
||||
|
File extraction |
The File extraction is on option is selected by default. The related Extract options are also selected by default and may be cleared independently, if desired. If this option is disabled (the related Extract options are also cleared) and data is submitted for extraction, no extraction occurs from file types, such as mail stores and archives. This enables documents to be sent through Streaming Discovery knowing that all the docs were already extracted including file parents (e.g., emails and edocs).
|
||||
|
OCR |
Configure your OCR settings. Optical Character Recognition is used to identify and extract text from image-based files that can be indexed and searched in Review. To use OCR on image-based files such as .pdf, .jpg, .bmp, .tiff, etc., ensure the slider at the top is set to OCR is on.
You can likewise set the following options:
|
||||
|
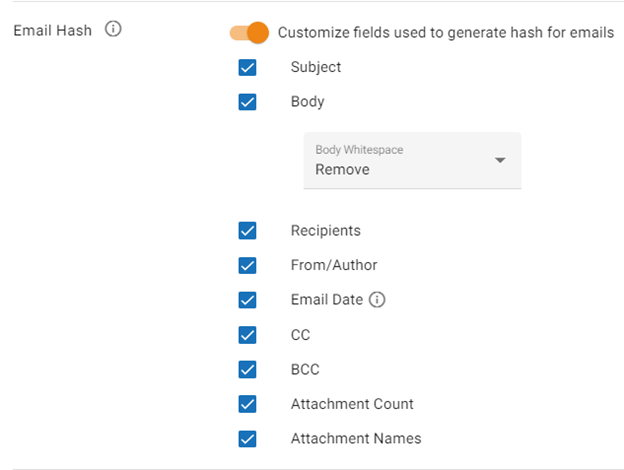
Email Hash |
When an email is discovered within OPEN DISCOVERY, it is assigned a hash value based on fields chosen by the user. The values of these fields are concatenated, and the text is hashed. Select from the following email fields to generate the hash value:
|

 to display the OCR Foreign Language dialog box.
to display the OCR Foreign Language dialog box. 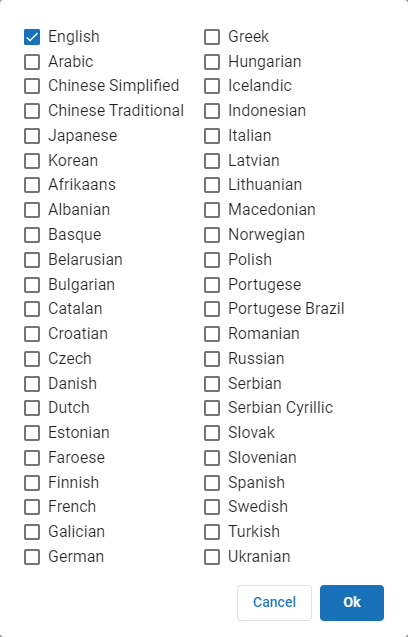
Related Topics